The Blog Post
We recently posted a (very long) law-review article about copyright and generative AI. We’re very excited to announce that the piece has been accepted for publication at the Journal of the Copyright Society (JCS),Forthcoming in print, 2024
the premier publication venue for copyright scholars and practitioners!
Here, we’d like to provide a bit of a shorter version highlighting what we term the generative-AI supply chain, and how this supply-chain framework helps expose the (very many) places where generative AI touches on copyright considerations. As a concrete example, we detail issues of substantial similarity and the generation stage of the supply chain. We then showcase our article’s main takeaways.
We believe that copyright is a fantastic case study for stepping through the complexities of evaluating and using generative-AI systems in all sorts of contexts. So, while our piece specifically engages with the nuts and bolts of US copyright law, we write our supply-chain framing to be more broadly applicable.
One of our big goals is that this framing helps promote the development of better, more useful systems — especially as an increasing number of actors and stakeholders start using (or have their works used for training) generative-AI applications. Somewhat more modestly, we also hope this blog post gives a flavor of the longer piece, and will sufficiently pique your interest to go read it.
Introduction
We begin by asking the question, “Does generative AI infringe copyright?” This is an urgent question, and, while it’s simple to state, it’s difficult to answer for two reasons. First, “generative AI” is not just one product from one company. It’s a catch-all name for a massive ecosystem of loosely related technologies. These systems behave differently and raise different legal issues. Second, copyright law is notoriously complicated, and generative-AI systems manage to touch on a great many corners of it. They raise issues of authorship, similarity, direct and indirect liability, safe harbors, licensing, and fair use, among much else. These issues cannot be analyzed in isolation, because there are connections everywhere.
In our full article, we aim to bring order to the chaos. To do so, we introduce the generative-AI supply chain: an interconnected set of eight stages that transform training data into generations (Figure 1). These stages are:
- production of creative works
- conversion of creative works into quantified data
- creation and curation of training datasets
- base model (pre-)training
- model fine-tuning to adapt to a specific problem domain
- model release or deployment within a software system
- generation
- alignment, i.e., adjusting the model and system to advance goals (such as helpfulness, safety, legal compliance)
The supply chain is not a simple cascade from data to generations. Instead, each stage is regularly adjusted to better meet the needs of the others.
Breaking down generative AI into these constituent stages reveals all of the places at which companies and users make choices that have copyright consequences. It enables us to trace the effects of upstream technical designs on downstream uses, and to assess who in these complicated sociotechnical systems bears responsibility for infringement when it happens. Because we engage so closely with the technology of generative AI, we are able to shed more light on the copyright questions. We identify the key decisions that courts will need to make as they grapple with these issues, and point out the consequences that would likely flow from different liability regimes.Unfortunately, we omit the (extensive) footnotes that we include in the full article. It feels wrong, but it’s necessary for this format.
A Note on Generative-AI Systems
One of our introductory interventions is to emphasize that there is a difference between generative-AI models and generative-AI systems. Most users of generative AI do not interact with a model directly. Instead, they use an interface to a system, in which the model is just one of several embedded, inter-operating components. For example, OpenAI hosts various ways to access its latest GPT models. ChatGPT is a user interface, where the priced version is currently built on top of the GPT-4 model architecture. OpenAI also has a developer API, which serves as an interface for programmers to access different models. There are additional components behind each of these interfaces, including possibly (according to rumor) as many as sixteen GPT-4 models, to which different prompts are routed. As another example, consider Stable Diffusion, an open-source model for producing image generations. Most users do not interact directly with the Stable Diffusion model; rather, they typically access a version that is embedded in a larger system operated by Stability AI, which has multiple components, including a web-based application called DreamStudio. In our article, we focus on generative-AI systems, rather than generative-AI models, to highlight how models are just one (however, important) component of an entire system. This focus is particularly important when we introduce our framing of the generative-AI supply chain.
The Generative-AI Supply Chain
In the article, we provide some preliminary details on machine learning (ML) and generative AI. But here, we assume introductory familiarity with both and delve right into our discussion. To begin, we note that one of the big enablers of today’s generative-AI systems is scale. Notably, scale complicates what technical and creative artifacts are produced, when these artifacts are produced and stored, and who exactly is involved in the production process. In turn, these considerations are important for how we reason about copyright implications: what is potentially an infringing artifact, when in the production process it is possible for infringement to occur, and who is potentially an infringing actor.
We introduce the generative-AI supply chain as a way to provide some structure for reasoning about these considerations. We conceive of there being eight stages, illustrated in Figure 1: 1) production of creative works, 2) conversion of creative works into quantified data, 3) creation and curation of training datasets, 4) base model (pre-)training, 5) model fine-tuning, 6) model release or deployment within a software system, 7) generation, and 8) alignment. Each stage gathers inputs from prior stage(s) and hands off outputs to subsequent stage(s), which we indicate with (sometimes bidirectional) arrows. The connections between these supply-chain stages are complicated. In some cases, one stage clearly precedes another (e.g., model pre-training necessarily precedes model fine-tuning), but, for other cases, there are many different possible ways stages can interact and may involve different actors. We highlight some of this complexity below, and provide significantly more detail in the full article.
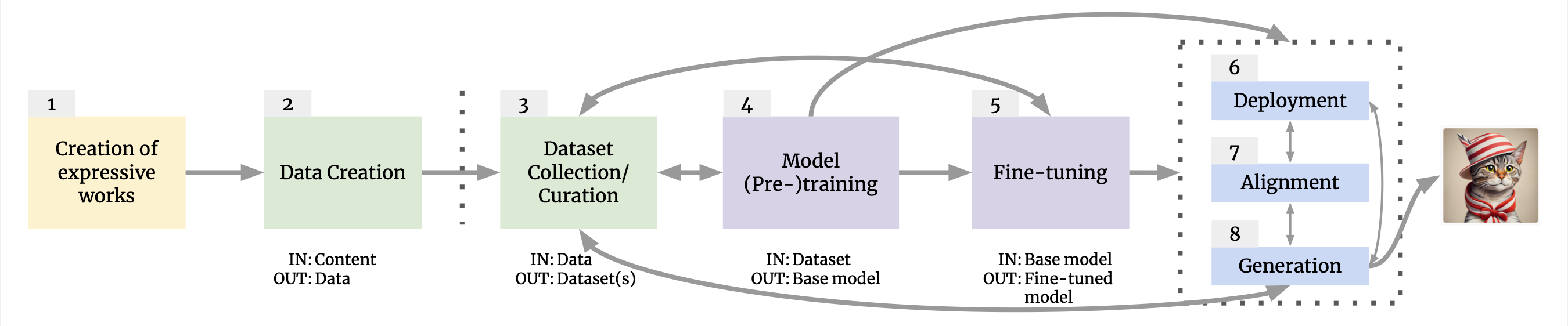
1. The Creation of Expressive Works
Artists, writers, coders, and other creators produce expressive works. Generative-AI systems do, too; but state-of-the-art systems are only able to do so because their models have been trained on data derived from pre-existing creative works. It is worth remembering that, historically, the production of most creative works has had nothing to do with ML. Painters have composed canvases, writers have penned articles, etc. without considering how their works might be taken up by automated processes. Nevertheless, these works can be transformed into quantified data objects that can serve as inputs for ML. They can be easily posted on the Internet and have circulated widely, making them accessible for the development of generative-AI systems. Thus, authors and their works are a part of the generative-AI supply chain—whether they would like to be or not (Figure 1, stage 1).
2. Data Creation
Original expressive works are distinct from their datafied counterparts. Data examples are constructed to be computer-readable, such as the JPEG encoding of a photograph. For the most part, the transformation of creative content to data formats predates generative AI (Figure 1, stage 2), but all state-of-the-art generative-AI systems depend on it. Text-to-text generation models are trained on digitized text, text-to-image models are trained on both text and images, text-to-music models are trained on text and audio files, and so on. This is an important point because works that have been transformed into data have been fixed in a tangible medium of expression, and therefore are subject to copyright. In turn, generative-AI systems are often trained on data that includes copyrighted expression. The GitHub Copilot system involves models trained on copyrighted code, ChatGPT’s underlying models are trained on text scraped from the web, Stability AI’s Stable Diffusion is trained on text and images, and so on. For the most part, it is the copyright owners of these datafied individual works who are the potential plaintiffs in an infringement suit against actors at other stages of the supply chain.
3. Dataset Collection and Curations
The training process for cutting-edge generative-AI models requires vast quantities of data. Dataset creators often meet this need by scraping the Internet. This process involves numerous curatorial choices, including filtering out material that creators do not want to include, such as “toxic speech.” Thus, dataset creators are also necessarily curators.
With respect to the generative-AI supply chain, there are several points worth highlighting (Figure 1, stage 3). First, while dataset creation and curation can be carried out by the same entities that train generative-AI models, it is common for them to be split across different actors. The Stable Diffusion model, for example, is trained on images from datasets curated by LAION, a organization. It is necessary, therefore, to consider the liability of dataset creators separately from the liability of model trainers.
Second, dataset curation will frequently involve “the collection and assembling of preexisting materials or of data that are selected, coordinated, or arranged in such a way that the resulting work as a whole constitutes an original work of authorship” (17 U.S.C. § 101). Thus, training datasets can themselves be copyrighted; copying of the dataset as a whole without permission could constitute infringement, separate and apart from infringement on the underlying works.
Third, while a few datasets include metadata on the provenance of their data examples, many do not. Provenance makes it easier to answer questions about the sources a model was trained on, which can be relevant to infringement analysis. It also bears on the ease with which specific material can be located, and if necessary removed, from a dataset. However, the use of web-scraping to collect generative-AI training datasets makes provenance difficult to track. Even if a dataset creator releases the dataset itself under a license, this does not guarantee that the works in the dataset are appropriately licensed, as is currently up for debate with the LAION-5B dataset.
4. Model (Pre-)Training
Following the collection and curation of training datasets, it is possible to train a generative-AI model. A model trainer (Figure 1, stage 4) selects a training dataset, a model architecture, a training algorithm, and a seed value for the random choices made during the training. The process of transforming these inputs into a trained model is expensive. It requires a substantial investment of multiple resources: time, data storage, and compute. For example, BLOOM (a 176-billion-parameter open-source model from HuggingFace) was trained for 3.5 months, on 1.6 terabytes of text, using 384 GPUs; it cost an estimated $2-5 million. Altogether, the dollar cost can range from six to eight figures.
The output of the training process is typically called a pre-trained model or base model. A base model has many possible futures. It could sit idly in memory, collecting figurative dust. The model could be uploaded to a public server, allowing others to download it and use it however they want. The model could be integrated into a system and deployed as a public-facing application, which others could use directly to produce generations. Or, the model could be further modified by the initial model trainer, by another actor at the same organization, or, if made publicly available, a different actor from a different organization. That is, another actor could take the model parameters and use them as the input to do additional training with new or modified data.
This possibility of future further training of a base model is why this stage of the supply chain is most often referred to as pre-training, and why a base model is similarly often called a pre-trained model. Such additional training of the base model is called fine-tuning.
5. Model Fine-Tuning
Base models trained on large-scale, web-scraped datasets are not typically optimized to apply specialized domains of knowledge. For example, an English text-to-text base model may be able to capture general English-language semantics, but not able to reliably apply detailed scientific information about molecular biology.
This is where fine-tuning comes in (Figure 1, stage 5). Fine-tuning is the process of modifying a pre-existing model and making it better along some dimension of interest. This process often involves training on additional data that is more aligned with the specific goals. If we think of training as transforming data into a model, fine-tuning transforms a model into another model. Even though fine-tuning and pre-training are both just training, they are run with different inputs. This ultimately makes the trajectories and outputs of their respective training processes very different. To add more precision to our previous statement: fine-tuning transforms a model into another model, while incorporating more data.
Forks in the supply chain
Prior to fine-tuning, there is a fork in the generative-AI supply chain, with respect to the possible futures of the base model after pre-training (stage 4). One does not have to fine-tune at all. They could take the output base model from pre-training, and use this model directly as the input for system deployment (stage 6), generation (stage 7), or model alignment (stage 8). Alternatively, it is possible to perform multiple separate passes of fine-tuning — to take an already-fine-tuned model, and use it as the input for another run of fine-tuning on another dataset.
For each possibility, there can be different actors involved. Sometimes, the creator of a model also fine-tunes it. Google’s Codey models (for code generation) are fine-tuned versions of Google’s PaLM 2 model. In other cases, when a model’s parameters are publicly released (as Meta has done with its Llama family of models), others can take the model and independently fine-tune them for particular applications. A Llama fine-tuner could release their model publicly, which in turn could be fine-tuned by another party. To use a copyright analogy, a fine-tuned model is a derivative of the model from which it was fine-tuned; a repeatedly fine-tuned model is a derivative of the (chain of) fine-tuned model(s) from which it was fine-tuned.
It’s helpful to make the base-/fine-tuned model distinction because different parties may have different knowledge of, control over, and intentions toward choices like which data is used for training and how the resulting trained model will, in turn, be put to use. A base-model creator, for example, may attempt to train the model to avoid generating copyright-infringing material. However, if that model is publicly released, someone else may attempt to fine-tune the model to remove these anti-infringement guardrails. A full copyright analysis may require treating them differently and analyzing their conduct in relation to each other.
6. Model Release and System Deployment
It’s possible to release a model or deploy it as part of a larger software system, use the model to produce generations, or to take the model and further alter or refine it via model alignment techniques. In brief, there is a complicated interrelationship between the deployment, generation, and alignment stages. They can happen in different orders, in different combinations, and at different times for different generative-AI systems. For purely expository purposes, we present them one at a time, starting with model release and system deployment (Figure 1, stage 6).
External-facing services can be deployed in a variety of forms, and do not typically include the ability to change the model’s parameters. They can be browser-based user applications (e.g., ChatGPT, Midjourney, DreamStudio), or public (but not necessarily free) APIs for developers (e.g., GPT models, Cohere). Some model trainers provide a combination of release and deployment options. For example, DreamStudio is a web-based user interface built on top of services hosted by Stability AI; the DreamStudio application gives external users access to a generative-AI system that contains the open-source Stable Diffusion model, which Stability AI also makes available for direct download.
These deployment methods offer varying degrees of customization and control on the part of the deployer and the user. Typically, model trainers and owners maintain the most control over models deployed through hosted services and the least over models released as model parameters. By embedding a model within a larger system, they can imbue it with additional behaviors. APIs and web applications allow deployers to filter a model’s inputs or outputs. For example, GitHub Copilot expressly states that it uses “filters to block offensive words in the prompts and avoid producing suggestions in sensitive contexts.” Unfortunately, output filtering is an imperfect process.
7. Generation
Generative-AI models produce output generations in response to input prompts. Users can affect generations in a few ways. First, there is the prompt itself. Some prompts, like “a big dog”, are simple and generic. Others, such as “a big dog facing left wearing a spacesuit in a bleak lunar landscape with the earth rising as an oil painting in the style of Paul Cezanne”, are more detailed. Second, users choose a deployed system (which embeds an implicit choice of model). For example, a user that wants to perform text-to-image generation on a browser-based interface needs to select between Ideogram, DALL·E-2, Midjourney, and other publicly available text-to-image applications that could perform this task. Users may also revise their prompt to attempt to create generations that more closely align with their goals. And, third, there is randomness in each generation. It is typical, for example, for image applications to produce four candidate generations. DALL·E-2, Midjourney, and Ideogram all do this.

"cat in a red and white striped hat" generated by the authors with Ideogram. Running the model (𝑓) multiple times on the same input can generate different outputs.
In our article, we show that characterizing the relationship between the user and the chosen deployed system is one of the critical choice points in a copyright-infringement analysis. There are at least three ways the relationship could be described:
- The user actively drives the generation through choice of prompt, and the system passively responds. In this view, the user is potentially a direct infringer, but the application is like a web host, ISP, or other neutral technological provider.
- The system is active and the user passive. In this view, the user is like a viewer of an infringing broadcast, or the unwitting buyer of a pirated copy of a book. Primary copyright responsibility lies with the deployed system, and possibly with others further upstream in the generative-AI supply chain.
- The user and system are active partners in generating infringing outputs. In this view, the user is like a patron who commissions a copy of a painting; the system is like the artist who executes it. They have a shared goal of creating an infringing work.
We argue that there is no universally correct characterization. Which of these three is the best fit for a particular act of generation will depend on the system, the prompt, how the system is marketed, and how users can interact with the system’s interfaces.
Forks in the supply chain
Generations may also feed back into dataset collection. While it is not universal, it is common to use generations as training data for generative-AI models. In this case, generation serves simultaneously as the creation of expressive works (i.e., stage 1) and data creation (i.e., stage 2), and generations can become inputs to dataset collection and curation processes (i.e., stage 3), which we indicate with an arrow in Figure 1. In the full article, we discuss how this potential circularity also has implications for copyright.
8. Model Alignment
The generative-AI supply chain does not end at generation. As discussed above, model trainers try to improve models during both pre-training and fine-tuning the base model. Both of these base model modifications are coarse: They make adjustments to the dataset and algorithm, and do not explicitly incorporate information into the model about whether specific generations are “good” or “bad,” according to user preferences.
There is a whole area of research, called model alignment, that attempts to meet this need. The overarching aim of model alignment is to align model outputs with specific generation preferences (see Figure 1, stage 8). Currently, the most popular alignment technique is called reinforcement learning with human feedback (RLHF). As the name suggests, RLHF combines collected human feedback data with a (reinforcement learning) algorithm in order to update the model.
Human feedback data can take a variety of forms, which include user ratings of generations. For example, such ratings can be collected by including thumbs-up and thumbs-down buttons in the application user interface, which are intended to query feedback about the system’s output generation. In turn, the reinforcement learning algorithm uses these ratings to adjust the model — to encourage more “thumbs-up” generations and fewer “thumbs-down” ones. Future training and alignment on the model may include both the inputted prompt and the generation in addition to the feedback provided. As discussed in the prior section, user-supplied prompts may include copyrighted content created by either the user themselves or by another party.
Most generative-AI companies begin model alignment prior to deployment or release. In this respect, model alignment complements other techniques, like input-prompt and output-generation filtering.
Copyright
In the article we discuss how the supply chain interacts with numerous aspects of United States copyright doctrine. We touch on authorship, exclusive rights, substantial similarity, proving copying, direct and indirect infringement, and paracopyright considerations. With respect to defenses against infringement, we discuss the DMCA Section 512 safe harbors, fair use, express and implied licenses. We also discuss possibilities for remedies.
Here, we first give some very preliminaries about copyright. Then, as an example of our analysis, here we go into detail on substantial similarity and generation (Figure 1, stage 7). In the article, we touch on all relevant aspects of the supply chain for each of the copyright concerns listed above.
Substantial Similarity and Generation
In this post, we aren’t going to get into the details of copyright doctrine (we defer to the paper). Instead, we’ll just note that US copyright applies to original, human-authored, original works fixed in a “tangible medium of expression” (17 U.S.C. § 102(a)). “Original, as the term is used in copyright, means only that the work was independently created by the author (as opposed to copied from other works), and that it possesses at least some minimal degree of creativity.”Feist Publ’ns v. Rural Tel. Serv. Co., 499 U.S. 340, 345 (1991)
. Fixation is satisfied when the work is embodied in a tangible object in a way that is “sufficiently permanent or stable to permit it to be perceived, reproduced, or otherwise communicated for a period of more than transitory duration” (17 U.S.C. § 101). Copyrightable subject matter explicitly includes “literary works” (e.g. poems, novels, FAQs, and fanfic), “musical works” (e.g., sheet music and MIDI files)272 “pictorial . . . works” (e.g. photographs), “audiovisual works” (e.g., Hollywood movies and home-recorded TikToks), “sound recordings” (e.g., pop songs and live comedy recordings), and more (17 U.S.C. § 102(a)(2,5,6,7)) .
In lawsuits about copyright infringement, courts evaluate if a defendant has engaged in conduct that violates the copyright owner’s exclusive rights (e.g., reproducing or publicly distributing content that contains the copyrighted material). In these evaluations, one important consideration is substantial similarity between the copyrighted work and the alleged infringing work in question.
Substantial similarity is a qualitative, factual, and frustrating question. Two works are substantially similar when “the ordinary observer, unless he set out to detect the disparities, would be disposed to overlook them, and regard their aesthetic appeal as the same”Peter Pan Fabrics, Inc. v. Martin Weiner Corp., 274 F.2d 487, 489 (2d Cir. 1960) (Hand, J.)
. A common test is a “holistic, subjective comparison of the works to determine whether they are substantially similar in total concept and feel”Rentmeester v. Nike, Inc., 883 F.3d 1111, 1118 (9th Cir. 2018)
. This is not a standard that can be reduced to a simple formula that can easily be applied across different works and genres.
Some generations are nearly identical to a work in the model’s training data (i.e., memorized, see Figure 3). They are substantially similar to that work. Other generations are very dissimilar from every work in the training data. In the second case, there is no substantial similarity, because infringement is assessed on a work-by-work basis. Although it is in some sense based on all of the works in the training dataset, it does not infringe on any of them. The hardest case is when an output is similar to a work in the training data in some ways, but dis- similar from it in other ways. This case is likely to arise in practice precisely because it lies in between the two extremes of memorized generations and original generations. Somewhere between them lies the murky frontier between infringing and non-infringing generations.

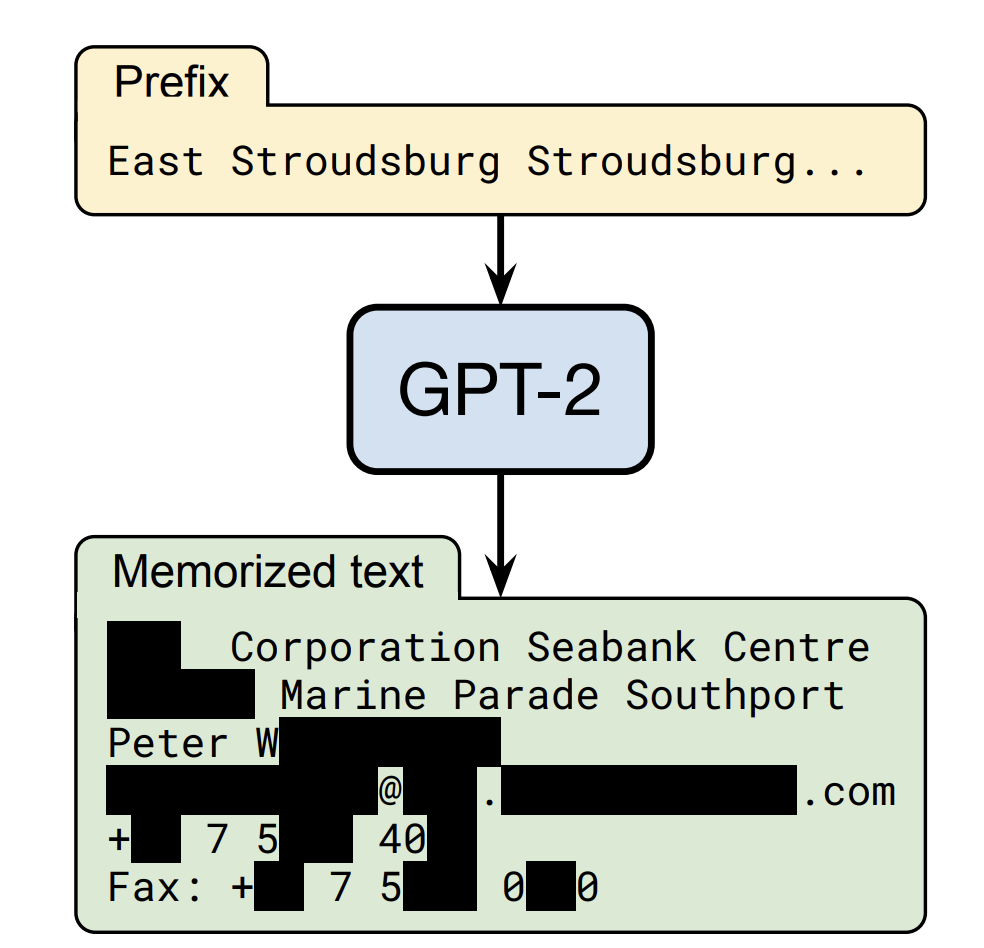
It is hard to make sweeping statements. Whether a particular generation is substantially similar is ultimately a jury question requiring assessment of audiences’ subjective responses to the works. Generative AI will produce cases requiring this lay assessment; it is impossible to anticipate in advance how lay juries will react to all of the possible variations. So, we will assume that lay audiences would say that some generations will infringe, but that it will not be possible to perfectly predict which ones.

"4 cartoon Snoopy beagles walking across a crosswalk, ink illustration in the style of a cartoon illustration cel, the Beatles, dark background with vintage accents, background text: “The Beagles”". Generated by the authors on Ideogram, adapted from an anonymous prompt on the Ideogram website.
Even if complete answers are impossible, there are some interesting questions worth considering. As Matthew Sag observes, certain characters are so common in training datasets that models have “a latent concept [of them] that is readily identifiable and easily extracted.”Matthew Sag, Copyright Safety for Generative AI, Hous. L. Rev. (forthcoming).
For example, prompting Midjourney and Stable Diffusion with “snoopy” produces recognizable images of Snoopy the cartoon beagle.
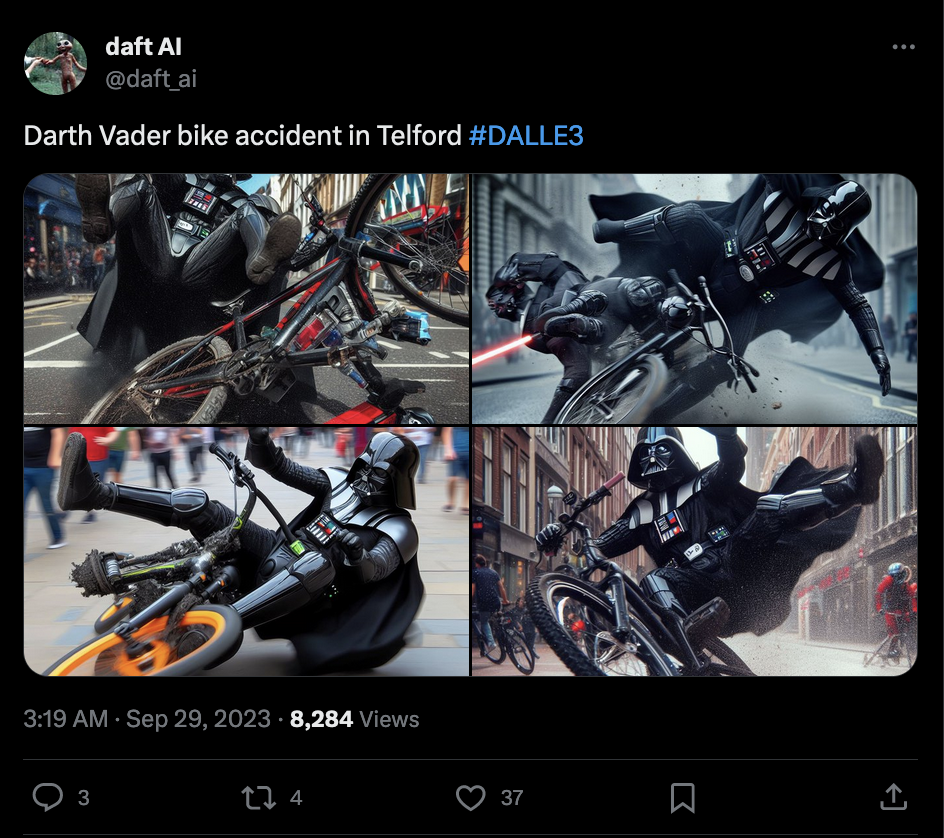
”Darth Vader bike accident in Telford”.
Characters are a special case in copyright; some cases relax the rule that infringement is measured on a work-by-work basis, instead measuring the similarity of the defendant’s character to one who appears in multiple works owned by the plaintiff. But the “Snoopy effect” is not confined to characters. Some works are simply so prevalent in training datasets that models memorize them. As an uncopyrighted example, Van Gogh’s Starry Night is easy to replicate using Midjourney; Sag’s paper includes a replication of Banksy’s Girl with Balloon. This looks like substantial similarity.
A variation of the Snoopy effect arises when a model learns an artist’s recognizable style. ChatGPT can be prompted to write rhyming technical directions in the style of Dr. Seuss; DALL·E-2 can be prompted to generate photorealistic portraits of nonexistent people in the style of Dorothea Lang (Figure 6). As with characters, these outputs have similarities that span a body of source works, even if they are not close to any one source work. The proper doctrinal treatment of style is a difficult question.
The Snoopy effect can also be triggered without explicit prompting. The archaeologist generated in Figure 7-left features a dark-haired male character with stubble, wearing a brown jacket and white shirt, with a pouch slung across his shoulder. These are features associated with Indiana Jones, but neither the features nor “indiana jones” appear in the prompt. Some caselaw holds that such similarities are enough for infringement when the character is iconic enough.


"an adventurous archaeologist with a whip and a fedora", generated by the authors using Midjourney. Right: "ice princess", generated by the authors using Midjourney.
Other copyright doctrines, however, may limit infringement in Snoopy-effect cases. One of them is scènes à faire: creative elements that are common in a genre cannot serve as the basis of infringement. For example, prompting Midjourney with “ice princess” produces portraits of women in shades of blue and white with flowing hair and ice crystals (Figure 7-right). Similarities to Elsa from Frozen could arise simply because these are standard tropes of wintry glamor. Some of them may now be tropes because of the Frozen movies, but they are still uncopyrightable ideas, rather than protectable expression.
We note that not all similarity is infringing. Some similarities arise for innocent reasons. The defendant and the plaintiff might both have copied from a common predecessor work, and resemble each other because they both resemble the work they were based on. The similarities might consist entirely of accurate depictions of the same preexisting thing, like Grand Central Station.
Which Way from Here?
The generative-AI supply chain is extremely complex. So is copyright law. Putting the two of them together multiplies the intricacy, which we explore in detail in the full article. Two unsettling conclusions follow.
First, because of the complexity of the supply chain, it is not possible to make accurate sweeping statements about the copyright legality of generative AI. Too much depends on the details of specific systems. All the pieces matter, from the curatorial choices in the training dataset, to the training algorithm, to the deployment environment, to the prompt supplied by the user. Courts will have to work through these details in numerous lawsuits and develop doctrines to distinguish among different systems and uses.
Second, because of the complexity of copyright law, there is enormous play in the joints. Substantial similarity, fair use, and other doctrinal areas all have open-ended tests that can reach different results depending on the facts a court emphasizes and the conclusions it draws. This complexity gives courts the flexibility to deal with variations in the supply chain. Paradoxically, it also gives courts the freedom to reach any of several different plausible conclusions about a generative-AI system.
In the article, we discuss ways that courts might use their discretion to apply copyright law to generative AI. We cover possible outcomes of no liability, liability for generations only, notice and removal, and infringing models. We then discuss some of the considerations that courts should keep in mind.
Here, we limit ourselves to discussing these considerations. In keeping with our bottom line — the generative-AI supply chain is too complicated to make sweeping rules prematurely — we offer a few general observations about the overall shape of copyright and generative AI that courts and policymakers should keep in mind as they proceed.
1. Copyright touches every part of the generative-AI supply chain
Every stage from training data to alignment (including user inputs) can make use of copyrighted works. Generative AI also raises many other legal issues: Can a generative-AI system commit defamation? Can a generative-AI system do legal work and should they be allowed to? But these issues pertain to outputs of a generative-AI system — copyright pervades every step of the process.
2. Copyright concerns cannot be localized to a single link in the supply chain
Decisions made by one actor can affect the copyright liability of another actor far away in the supply chain. Whether an output looks like Snoopy or like a generic beagle depends on what images were collected in a dataset, which model architecture and training algorithms are used, how trained models are fine-tuned and aligned, how models are embedded in deployed services, what the user prompts with, etc. Every single one of these steps could be under the control of a different person.
3. Design choices matter
There are obvious choices throughout the generative-AI supply chain that could implicate copyright: whether to train on licensed or unlicensed data at all (which can affect downstream risks, such as producing generations that are substantially similar to copyright works); and how to respond to notices that a system is producing potentially infringing generations (which, in turn, can affect upstream risks, if generated content is used for future training), etc.
But subtler model training and architectural choices matter, too. Different settings on a training algorithm can affect how much the resulting model will memorize specific works. Different deployment environments can affect whether users have enough control over a prompt to steer a system towards infringing outputs. Copyright law will have to engage with these choices — as will AI policy.

4. Fair use is not a silver bullet
For a time, it seemed that training and using AI models would often constitute fair use (there are countless other deployed AI/ML systems that pre-date generative AI). In such a world, AI development is generally a low-risk activity, at least from a copyright perspective. Yes, training datasets and models and systems may all include large quantities of copyrighted works — but those works will never be shown to users. For example, in prediction systems, users see outputs like classifications (e.g., whether an input image is a dog or a cat) or numerical values (e.g., how many ice cream cones a store expected to sell on July 1st).
Outputs like these have not been treated as expressive. Generative AI, however, scrambles this assumption. The serious possibility that some generations will infringe means that the fair-use analysis at every previous stage of the supply chain is up for grabs again.
5. The ordinary business of copyright law still matters
Courts will need to make old-fashioned, retail judgments about individual works — e.g., how much does this image resemble Elsa in particular, rather than tropes of fantasy princesses? Courts must leave themselves room to continue making these retail judgments on a case-by- case basis, responding to the specific facts before them, just as they always have. Perhaps eventually as society comes to understand what uses generative AI can be put to and with what consequences, it will reconsider the very fundamentals of copyright law. But until that day, we must live with the copyright system we have. And that system cannot function unless courts are able to say that some generative-AI systems and generations infringe, and others do not.
6. Analogies can be misleading
There are a lot of analogies for generative AI bouncing around. For example, a generative-AI model or system is like a search engine, or like a website, or like a library, or like an author, or like any number of other people and things that copyright has a well-developed framework for dealing with. These analogies are useful, but we wish to warn against treating any of them as definitive. As we have seen, generative AI is and can consist of many things. It is also literally a generative technology: it can be put to an amazingly wide variety of uses. And one of the things about generative technologies is that they cause convergence. Precisely because they can emulate many other technologies, they blur the boundaries between things that were formerly distinct. Generative AI can be like a search engine, and also like a website, a library, an author, and so on — but it is not exclusively nor always so. Prematurely accepting one of these analogies to the exclusion of the others would mean ignoring numerous relevant similarities — precisely the opposite of what good analogical reasoning is supposed to do.
Concluding Thoughts
We hope you enjoyed this brief tour of our article, and that it’s left you inclined to read the longer version (including the notes therein). In the full paper, we take care to spend the necessary space on ML and generative AI preliminaries (what’s new and what’s not-so-new for generative AI). This enables us to go into greater detail about particular interesting cases for copyright law (e.g., implications for diffusion-based image generation user interfaces and the display right).
We hope that our work provides clarity and useful framing for many of the big, unfolding conversations happening around generative AI — in legal scholarship, tech policy, labor strikes, the courtroom, and more.
Please don’t hesitate to reach out if you have any questions: [email protected], or reach the authors directly.
Acknowledgements
Our thanks to the organizers and participants of the Generative AI + Law workshop, and to Jack M. Balkin, Aislinn Black, Miles Brundage, Christopher Callison-Burch, Nicholas Carlini, Madiha Zahrah Choksi, Christopher A. Choquette-Choo, Christopher De Sa, Fernando Delgado, Jonathan Frankle, Deep Ganguli, Daphne Ippolito, Matthew Jagielski, Gautam Kamath, Mark Lemley, David Mimno, Niloofar Mireshghallah, Milad Nasr, Pamela Samuelson, Ludwig Schubert, Andrew F. Sellars, Florian Tramèr, Kristen Vaccaro, and Luis Villa.